What Is Undo and Why?
Oracle Database has a method of maintaining information that is used to rollback or undo the changes to the database. Oracle Database keeps records of actions of transactions, before they are committed and Oracle needs this information to rollback or undo the changes to the database. These records are called rollback or undo records.
These records are used to:
- Rollback transactions - when a ROLLBACK statement is issued, undo records are used to undo changes that were made to the database by the uncommitted transaction.
- Recover the database - during database recovery, undo records are used to undo any uncommitted changes applied from the redolog to the datafiles.
- Provide read consistency - undo records provide read consistency by maintaining the before image of the data for users who are accessing the data at the same time that another user is changing it.
- Analyze data as of an earlier point in time by using Flashback Query.
- Recover from logical corruptions using Flashback features.
Space for undo segments is dynamically allocated, consumed, freed, and reused — all under the control of Oracle Database, rather than by DBA.
From Oracle 9i, the rollback segments method is referred as "Manual Undo Management Mode" and the new undo tablespaces method as the "Automatic Undo Management Mode".
Notes:
- Although both rollback segments and undo tablespaces are supported, both modes cannot be used in the same database instance, although for migration purposes it is possible, for example, to create undo tablespaces in a database that is using rollback segments, or to drop rollback segments in a database that is using undo tablespaces. However, you must bounce the database in order to effect the switch to another method of managing undo.
- System rollback segment exists in both the modes.
- When operating in automatic undo management mode, any manual undo management SQL statements and initialization parameters are ignored and no error message will be issued e.g. ALTER ROLLBACK SEGMENT statements will be ignored.
Automatic Undo Management
What is UNDO_MANAGEMENT
The following initialization parameter setting causes the STARTUP command to start an instance in automatic undo management mode:
UNDO_MANAGEMENT = AUTO
The default value for this parameter is MANUAL i.e. manual undo management mode.
What Is UNDO_TABLESPACE
UNDO_TABLESPACE an optional dynamic parameter, can be changed online, specifying the name of an undo tablespace to use. An undo tablespace must be available, into which the database will store undo records. The default undo tablespace is created at database creation, or an undo tablespace can be created explicitly.
When the instance starts up, the database automatically selects for use the first available undo tablespace. If there is no undo tablespace available, the instance starts, but uses the SYSTEM rollback segment for undo. This is not recommended, and an alert message is written to the alert log file to warn that the system is running without an undo tablespace. ORA-01552 error is issued for any attempts to write non-SYSTEM related undo to the SYSTEM rollback segment.
If the database contains multiple undo tablespaces, you can optionally specify at startup that you want an Oracle Database instance to use a specific undo tablespace. This is done by setting the UNDO_TABLESPACE initialization parameter.
UNDO_TABLESPACE = undotbs1
In this case, if you have not already created the undo tablespace, the STARTUP command will fail. The UNDO_TABLESPACE parameter can be used to assign a specific undo tablespace to an instance in an Oracle Real Application Clusters (RAC) environment.
To findout the undo tablespaces in database
SQL> select tablespace_name, contents from dba_tablespaces where contents = 'UNDO';
To findout the current undo tablespace
SQL> show parameter undo_tablespace
(OR)
SQL> select VALUE from v$parameter where NAME='undo_tablespace';
UNDO_RETENTION
Committed undo information normally is lost when its undo space is overwritten by a newer transaction. However, for consistent read purposes, long-running queries sometimes require old undo information for undoing changes and producing older images of data blocks. The success of several Flashback features can also depend upon older undo information.
The default value for the UNDO_RETENTION parameter is 900. Retention is specified in units of seconds. This value specifies the amount of time, undo is kept in the tablespace. The system retains undo for at least the time specified in this parameter.
You can set the UNDO_RETENTION in the parameter file:
UNDO_RETENTION = 2000 (in secounds)
You can change the UNDO_RETENTION value at any time using:
SQL> ALTER SYSTEM SET UNDO_RETENTION = 3000; (in secounds)
The effect of the UNDO_RETENTION parameter is immediate, but it can only be honored if the current undo tablespace has enough space. If an active transaction requires undo space and the undo tablespace does not have available space, then the system starts reusing unexpired undo space (if retention is not guaranteed). This action can potentially cause some queries to fail with the ORA-01555 "snapshot too old" error message.
UNDO_RETENTION applies to both committed and uncommitted transactions since the introduction of flashback query feature in Oracle needs this information to create a read consistent copy of the data in the past.
Oracle Database 10g automatically tunes undo retention by collecting database use statistics and estimating undo capacity needs for the successful completion of the queries. You can set a low threshold value for the UNDO_RETENTION parameter so that the system retains the undo for at least the time specified in the parameter, provided that the current undo tablespace has enough space. Under space constraint conditions, the system may retain undo for a shorter duration than that specified by the low threshold value in order to allow DML operations to succeed.
The amount of time for which undo is retained for Oracle Database for the current undo tablespace can be obtained by querying the TUNED_UNDORETENTION column of the V$UNDOSTAT dynamic performance view.
SQL> select tuned_undoretention from v$undostat;
Automatic tuning of undo retention is not supported for LOBs. The RETENTION value for LOB columns is set to the value of the UNDO_RETENTION parameter.
Retention Guarantee
Oracle Database 10g lets you guarantee undo retention. When you enable this option, the database never overwrites unexpired undo data i.e. undo data whose age is less than the undo retention period. This option is disabled by default, which means that the database can overwrite the unexpired undo data in order to avoid failure of DML operations if there is not enough free space left in the undo tablespace.
You enable the guarantee option by specifying the RETENTION GUARANTEE clause for the undo tablespace when it is created by either the CREATE DATABASE or CREATE UNDO TABLESPACE statement or you can later specify this clause in an ALTER TABLESPACE statement. You do not guarantee that unexpired undo is preserved if you specify the RETENTION NOGUARANTEE clause.
In order to guarantee the success of queries even at the price of compromising the success of DML operations, you can enable retention guarantee. This option must be used with caution, because it can cause DML operations to fail if the undo tablespace is not big enough. However, with proper settings, long-running queries can complete without risk of receiving the ORA-01555 "snapshot too old" error message, and you can guarantee a time window in which the execution of Flashback features will succeed.
From 10g, you can use the DBA_TABLESPACES view to determine the RETENTION setting for the undo tablespace. A column named RETENTION will contain a value on GUARANTEE, NOGUARANTEE, or NOT APPLY (used for tablespaces other than the undo tablespace).
A typical use of the guarantee option is when you want to ensure deterministic and predictable behavior of Flashback Query by guaranteeing the availability of the required undo data.
Size of Undo Tablespace
You can size the undo tablespace appropriately either by using automatic extension of the undo tablespace or by manually estimating the space.
Oracle Database supports automatic extension of the undo tablespace to facilitate capacity planning of the undo tablespace in the production environment. When the system is first running in the production environment, you may be unsure of the space requirements of the undo tablespace. In this case, you can enable automatic extension for datafiles of the undo tablespace so that they automatically increase in size when more space is needed. By combining automatic extension of the undo tablespace with automatically tuned undo retention, you can ensure that long-running queries will succeed by guaranteeing the undo required for such queries.
After the system has stabilized and you are more familiar with undo space requirements, Oracle recommends that you set the maximum size of the tablespace to be slightly (10%) more than the current size of the undo tablespace.
If you have decided on a fixed-size undo tablespace, the Undo Advisor can help us estimate needed capacity, and you can then calculate the amount of retention your system will need. You can access the Undo Advisor through Enterprise Manager or through the DBMS_ADVISOR package.
The Undo Advisor relies for its analysis on data collected in the Automatic Workload Repository (AWR). An adjustment to the collection interval and retention period for AWR statistics can affect the precision and the type of recommendations the advisor produces.
Oracle Database provides an Undo Advisor that provides advice on and helps automate the establishment of your undo environment. You activate the Undo Advisor by creating an undo advisor task through the advisor framework. The following example creates an undo advisor task to evaluate the undo tablespace. The name of the advisor is 'Undo Advisor'. The analysis is based on AWR snapshots, which you must specify by setting parameters START_SNAPSHOT and END_SNAPSHOT.
In the following example, the START_SNAPSHOT is "101" and END_SNAPSHOT is "201".
DECLARE
tid NUMBER;
tname VARCHAR2(30);
oid NUMBER;
BEGIN
DBMS_ADVISOR.CREATE_TASK('Undo Advisor', tid, tname, 'Undo Advisor Task');
DBMS_ADVISOR.CREATE_OBJECT(tname,'UNDO_TBS',null, null, null, 'null', oid);
DBMS_ADVISOR.SET_TASK_PARAMETER(tname, 'TARGET_OBJECTS', oid);
DBMS_ADVISOR.SET_TASK_PARAMETER(tname, 'START_SNAPSHOT', 101);
DBMS_ADVISOR.SET_TASK_PARAMETER(tname, 'END_SNAPSHOT', 201);
DBMS_ADVISOR.execute_task(tname);
end;
/
Once you have created the advisor task, you can view the output and recommendations in the Automatic Database Diagnostic Monitor (ADDM) in Enterprise Manager. This information is also available in the DBA_ADVISOR_* data dictionary views.
In depth Explanation
Now we are looking basic workings of Automatic Undo Management, which can cause ORA-01555 and ORA-30036 issues.
The scope is Automatic Undo Management used in 10g and 11g, but has to be explicitly set for 9i (UNDO_MANAGEMENT = AUTO). Manual Undo Management is out of scope for this blog.
The Undo tablespace is a normal tablespace like any other, but only Oracle is controlling what is happening inside it.
Rollback
Rollback is easy to understand, if you are not happy with some data modifications, you want to ‘undo’ it: Rollback.
The original (non modified) information within a transaction is stored in a separate Undo tablespace, because the database is designed for COMMIT to be fast, not rolling back.
Read Consistency
Another mechanism Undo information is used for is Read Consistency, which means if you run a query at 9:00 for 10 minutes, you want all the data to be from 9:00. You don’t want it to read data that has been modified at 9:02 and 9:06 or data that hasn’t been committed yet.
So, to support Read Consistency, Oracle must keep the original data (committed or not) for these 10 minutes until the query is finished.
The problem is, you actually don’t know how long the query will run for, so the general rule is to set this ‘keep-old-data-period’ to the longest running query. This is because you also want your longest running query to read consistent data.
This ‘keep-old-data-period’ is called ‘UNDO_RETENTION’ and defaults to 900 seconds, which means the database tries to keep all old changed information for 900 seconds.
Flashback
Some Oracle features are build based upon using Undo information, meaning undo is more utilized.
Because ‘old’ data is stored for a certain time (UNDO_RETENTION), one can access this information to have look at data back in time by using FLASHBACK features: ‘How did the contents of this table looked like ten minutes ago?’. This information can be used for recovery from user-errors.
Flashback features using Undo are:
- Flashback Query (based on time)
- Flashback Versions Query (based on SCN)
- Flashback Transaction Query (based on period)
- Flashback Table (based on time)
Flashback Drop and Flashback Database do not use Undo information. Flashback Drop is using ‘not yet recycled segment and extents’ and Flashback Database is a separate mechanism using the Flash/Fast Recovery Area, by taking ‘snapshots’ and redo information.
Undo Lifetime
Undo information has different states during it’s lifecycle, depending on running transactions and retention settings.
There are three states or types of extents in the Undo tablespace: ACTIVE, EXPIRED and UNEXPIRED. Oracle is still using Rollback segments, but with Automatic Undo Management these are completely controlled by Oracle.
ACTIVE
Active undo extents are used by transactions and will always be active, because they are needed for Rollback. The UNDO_RETENTION setting is not used here, because one can not say something like: ‘after 900 seconds you are not allowed to rollback anymore…’
You will get ‘ORA-30036 unable to extend segment in Undo tablespace‘ errors when no more space is left to store ACTIVE Undo. This will automatically rollback the transaction causing it. The NOSPACEERRCNT column in V$UNDOSTAT is a good indication how many times this has occurred.
EXPIRED
Expired extents are not used by transactions, the data in these extends is committed and the UNDO_RETENTION time has passed, so it is not needed for Read Consistency.
UNEXPIRED
Unexpired extents are non-active extents that still honour UNDO_RETENTION. The transactions belonging to these undo extents are committed, but the retention time has not passed: You still want/need these for Read Consistency!
When the Undo mechanism requires more extents for ACTIVE extents, it is allowed to steal UNEXPIRED extents when there are no EXPIRED extents left for reuse and it can not allocate more free extents (autoextend maxsize reached or fixed tablespace size). One can check the steal-count in UNXPSTEALCNT in V$UNDOSTAT.
You will get ‘ORA-01555 snapshot too old‘ errors if no Read Consistency information for a query is available. TheSSOLDERRCNT in V$UNDOSTAT will show a count of these errors.
Undo extent status examples
With the next query you go through the contents of the Undo tablespace and sum the extent types:
select status,
round(sum_bytes / (1024*1024), 0) as MB,
round((sum_bytes / undo_size) * 100, 0) as PERCENT
from
(
select status, sum(bytes) sum_bytes
from dba_undo_extents
group by status
),
(
select sum(a.bytes) undo_size
from dba_tablespaces c
join v$tablespace b on b.name = c.tablespace_name
join v$datafile a on a.ts# = b.ts#
where c.contents = 'UNDO'
and c.status = 'ONLINE'
);
It will sum the three types of extents and shows the distribution of them within the Undo tablespace. ‘Free’ extents are not shown.
‘Normal’ operation
STATUS MB PERCENT
--------- ---------- ----------
ACTIVE 20 8
EXPIRED 220 86
UNEXPIRED 50 20
This is an example of ‘normal’ contents of the Undo tablespace. The system is using ACTIVE extents, some are UNEXPIRED used for read consistency and there are EXPIRED extents which can be reused.
Out of Free/EXPIRED extents
STATUS MB PERCENT
--------- ---------- ----------
ACTIVE 230 90
EXPIRED 0 0
UNEXPIRED 26 10
When the system is under load and the EXPIRED extents are near 0%, the total of ACTIVE and UNEXPIRED is near 100% and the Undo tablespace is not able to extend, Oracle will steal UNEXPIRED extents for ACTIVE extents. If this is the case you might expect ORA-01555 errors, because Undo retention can not be met.
Out of Undo space
STATUS MB PERCENT
--------- ---------- ----------
ACTIVE 255 100
EXPIRED 0 0
UNEXPIRED 1 0
When the system is under load and the ACTIVE extents are near 100%, the total of EXPIRED and UNEXPIRED is near 0% and the Undo Tablespace is not able to extend, Oracle is not able to allocate free extents or steal UNEXPIRED extents for ACTIVE extents. If this is the case you might expect ORA-30036 errors.
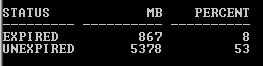
Retention to large or UNDO to small?
STATUS MB PERCENT
--------- ---------- ----------
ACTIVE 2 1
EXPIRED 0 0
UNEXPIRED 254 99
In this case, all undo extents are used for the retention period. It might be the retention is to large, or the UNDO tablespace is to small. A DBA must investigate this and take a decision!
Undo Sizing
Storing undo data for a certain amount of time will need space and based on the activity on the database system, it is written at a certain ‘rate’.
From this you can deduct an equation: RATE x RETENTION = SPACE. Some overhead must be added, but that varies between database versions used and data types stored.
If you look at the undo equation, the Undo tablespace size or the retention time can be fixed. A fixed rate can not be set, because it depends on database load.
Since Oracle 10g, the database will be more efficient if the same record is updated more than once in a transaction, it will re-use those ACTIVE extents.
Fixed Size
When the Undo tablespace size is fixed (datafile autoextend=NO), Oracle tunes the Retention Time for the amount of Undo data it is generating to fit into the Undo tablespace. The UNDO_RETENTION parameter will now be used as a minimum, but may automatically be tuned larger when enough space is available.
One can check the tuned Undo retention time in V$UNDOSTAT, using the TUNED_UNDORETENTION column.
In Oracle 9i, it seems Oracle is not actually tuning this, but is only trying to maintain the Undo retention time. Also the TUNED_UNDORETENTION column is absent in 9i.
When you choose the Undo tablespace to be fixed, you can use the Undo Advisor to estimate the needed sizing.
Fixed Size, out of UNEXPIRED extents? Check TUNED_UNDORETENTION!
STATUS MB PERCENT
--------- ---------- ----------
ACTIVE 2 1
EXPIRED 0 0
UNEXPIRED 254 99
Because Oracle is able to extend the retention time, more UNEXPIRED extents are created. In this case, if the Undo tablespace is full, check the TUNED_UNDORETENTION against UNDO_RETENTION. If the tuned retention is much larger, 99% full does not mean a problem!
Take a look at the following query, it will calculate the UNDO total with the following assumption: ACTIVE takes what is needs, EXPIRED ‘is empty’ and UNEXPIRED will be re-calculated against the division of UNDO_RETENTION/TUNED_UNDORETENTION.
BREAK ON REPORT
COMPUTE SUM OF MB ON REPORT
COMPUTE SUM OF PERC ON REPORT
COMPUTE SUM OF FULL ON REPORT
select status,
round(sum_bytes / (1024*1024), 0) as MB,
round((sum_bytes / undo_size) * 100, 0) as PERCENT,
decode(status, 'UNEXPIRED', round((sum_bytes / undo_size * factor) * 100, 0),
'EXPIRED', 0,
round((sum_bytes / undo_size) * 100, 0)) FULL
from
(
select status, sum(bytes) sum_bytes
from dba_undo_extents
group by status
),
(
select sum(a.bytes) undo_size
from dba_tablespaces c
join v$tablespace b on b.name = c.tablespace_name
join v$datafile a on a.ts# = b.ts#
where c.contents = 'UNDO'
and c.status = 'ONLINE'
),
(
select tuned_undoretention, u.value, u.value/tuned_undoretention factor
from v$undostat us
join (select max(end_time) end_time from v$undostat) usm
on usm.end_time = us.end_time
join (select name, value from v$parameter) u
on u.name = 'undo_retention'
);
When running this query, the next result will show when UNDO_RETENTION = 900 and TUNED_UNDORETENTION is about 1800 seconds:
STATUS MB PERCENT FULL
--------- ---------- ---------- ----------
ACTIVE 2 1 1
EXPIRED 0 0 0
UNEXPIRED 254 99 50
---------- ---------- ----------
sum 256 100 51
Unexpired at 99% is not really a problem here, because the tuned retention is twice as large as the desired retention!
Since 10gR2, a maximum retention is introduced. The longest period of tuned undo I have seen is 96 hours. Automatic tuning retention can also be turned off using the hidden ‘_undo_autotune=false’ parameter (don’t use until Oracle suggested this hidden parameter). See also My Oracle Support Note: Full UNDO Tablespace In 10gR2 [ID 413732.1].
Fixed/Auto Retention
If the Undo tablespace is configured with the autoextend option for the data files, Oracle sets the Retention Time to the time it takes for the longest-running query to run. This can result in a large Undo tablespace if there are un-tuned queries running on your system.
Again in 9i, even though it is called Automatic Undo Management, UNDO_RETENTION parameter seems always ‘fixed’, but it does mean you don’t have to bother about Rollback Segments.
Shrink Undo tablespace
The Undo tablespace can only grow larger, but it can not shrink by itself. If you want to shrink the Undo tablespace, create a new one and set the UNDO_TABLESPACE parameter to the new Undo tablespace.
Retention Guaranteed
When you create the Undo tablespace with the RETENTION GUARANTEE option, UNEXPIRED Undo information will never get stolen. Set this if you want to guarantee Read Consistency or when you want to use Flashback with a guaranteed point-in-time!
Beware that when this is set, the chance of ORA-30036 errors increases. It’s your choice: ORA-30036 or ORA-01555…
Setting the UNDO_RETENTION parameter to the longest running query
A good practice is to set the UNDO_RETENTION parameter to the longest running query, to avoid ORA-01555 (read consistency) errors. To get a good indication about the longest running query in the last 7 days, try:
select max(maxquerylen) from v$undostat;
One can also try V$SESSION_LONGOPS and V$TRANSACTION.
If you want to increase your Flashback period, take the largest of these two.
How much Undo will this generate?
Again take a look at V$UNDOSTAT and the UNDOBLKS column in particular.
Multiply these UNDOBLKS (per 10 minutes by default) times your BLOCKSIZE times the MAXQUERYLEN.
For a worst case scenario size you can calculate much undo would have been generated when you multiply the highest rate with the longest query:
select
round(max(undoblks/600)*8192*max(maxquerylen)/(1024*1024)) as "UNDO in MB"
from v$undostat;
But, it could be your longest running query will not run when the most undo is generated…
Note:- For this content I have taken refrence of blog of : Ian Hoogeboom and Sachin